From the source material
1 / 2
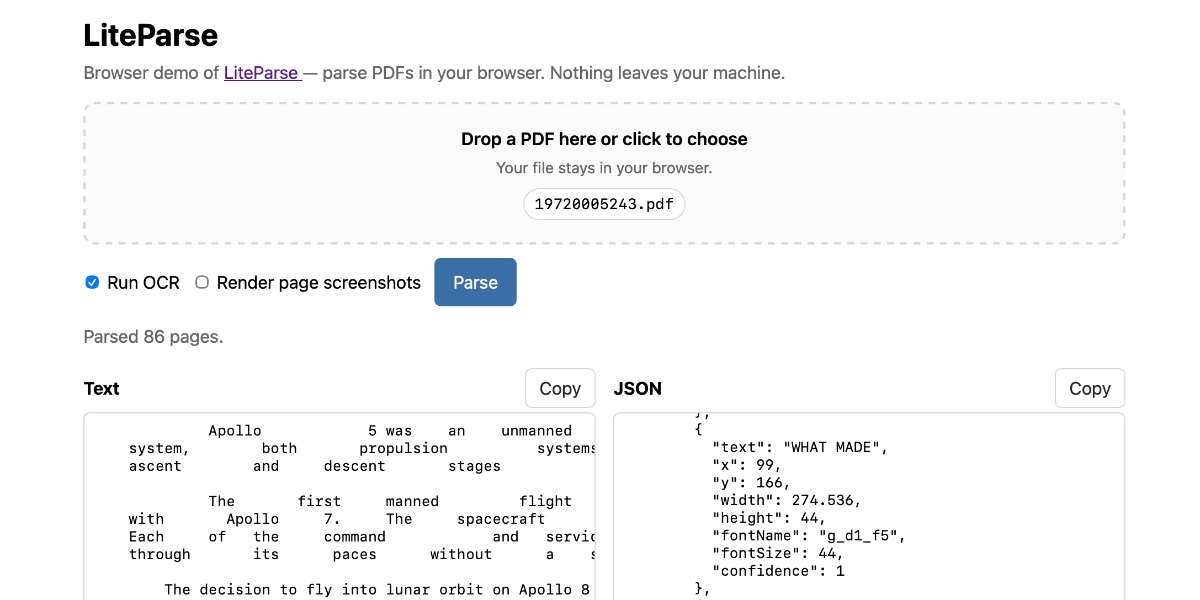
Image from Simon Willison.
2 / 2
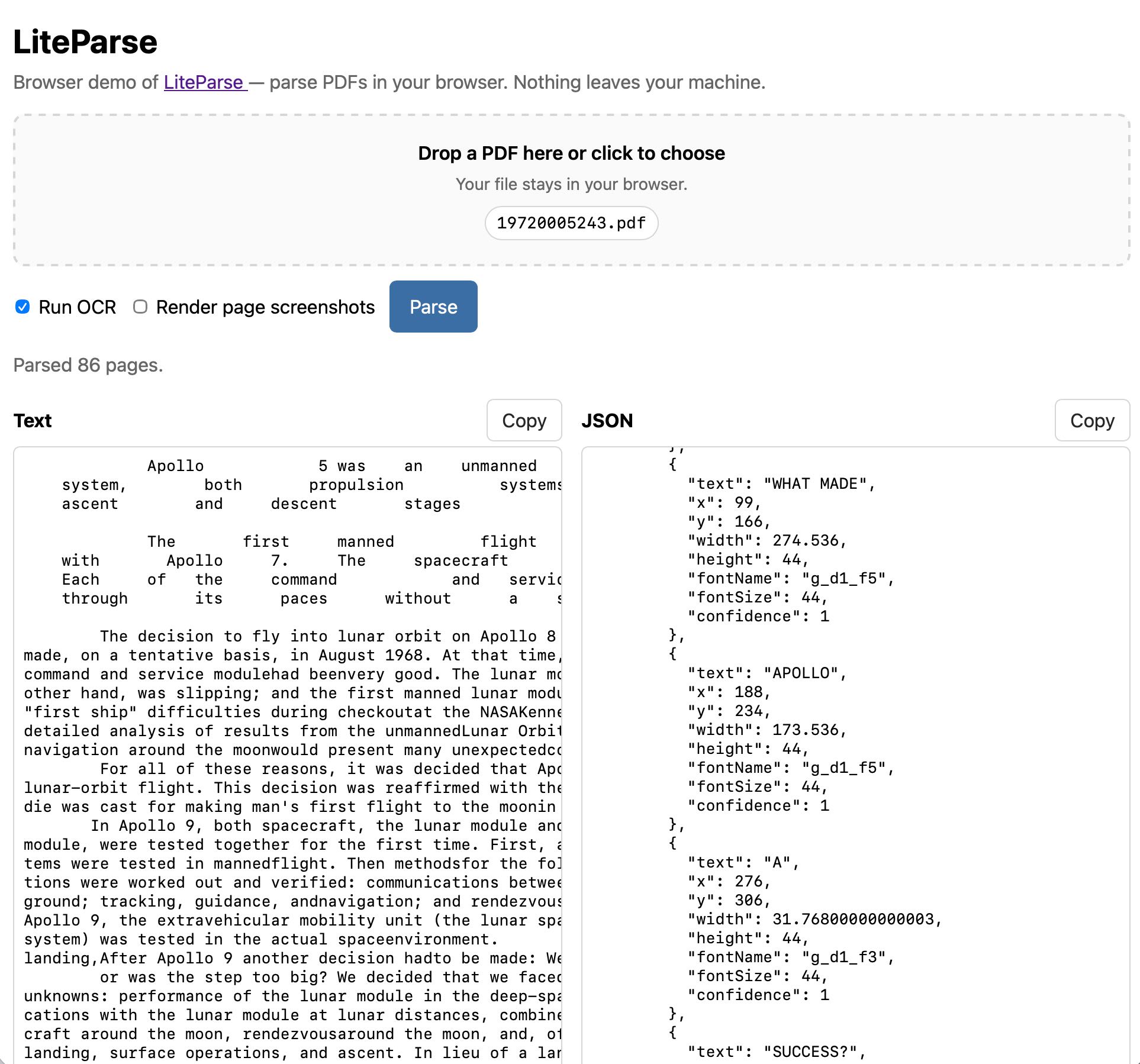
Image from Simon Willison.
The most valuable builder lesson this week didn't come from a frontier model benchmark. It came from Simon Willison getting LiteParse running in the browser. He used the same PDF.js and Tesseract.js machinery that powers the Node version, and it's a brilliant reminder of where document AI actually breaks.
LiteParse isn't an AI model; it's a deterministic PDF parser with OCR fallback and spatial heuristics for wrangling multi-column layouts. This is incredibly healthy. Your model should never be your first line of defense against a chaotic document. Anyone who has ever built document ingestion knows that PDFs are essentially frozen layout negotiations, complete with bizarre reading orders and rogue footnotes.
If extraction fails, everything downstream inherits the garbage—your search, your summaries, and your RAG pipelines all become useless. Running the parser in the browser changes the entire product shape. Users can extract and verify text locally before sending sensitive documents to a remote server. Security teams tend to appreciate smaller data boundaries.
This approach also allows for crucial intermediate artifacts. You get extracted text and page positions, making debugging possible. If a model hallucinates later, you can trace it back and see if the parser failed or if the model just lost its mind. LiteParse in the browser is a small demo with a massive moral: the boring plumbing of extraction is the highest-leverage step in document AI. Fix the parsing, and you stop the hallucinations at the source.
In short
Simon Willison ported LiteParse to the browser, proving once again that AI document workflows usually fail long before the model even sees the text.
Keep the signal coming
Useful AI, fewer talking points.
Follow Useful Machines for practical AI news, workflows, tools, and strategy. Sponsors can also evaluate whether this article belongs in the agents and developer tools lane.